Abstract
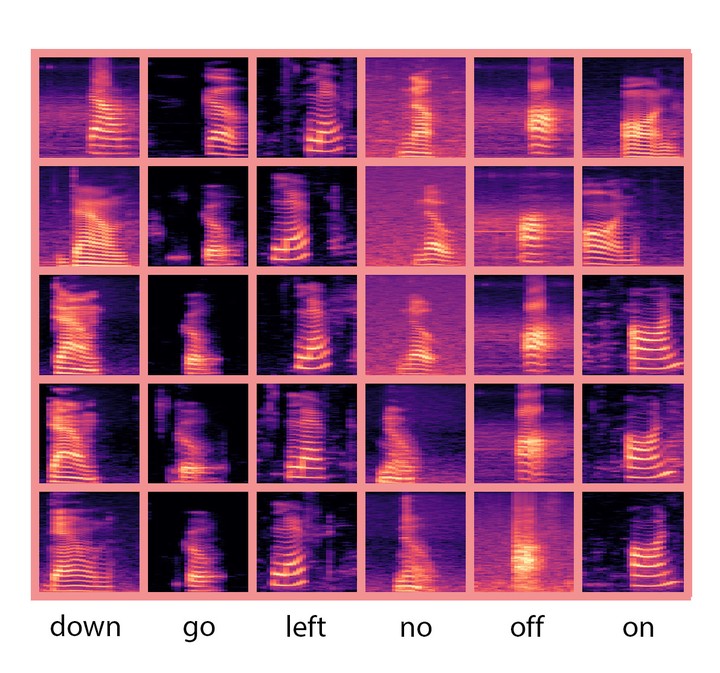
Convolutional Neural Networks (CNNs) work surprisingly well and has helped drastically enhance the state-of-the-art techniques in the domain of image classification. The unprecedented success motivated the application of CNNs to the domain of auditory data. Recent publications suggest Hidden Markov Models (HMMs) and Deep Neural Networks (DNNs) for audio classification. This paper aims to achieve audio classification by representing audio as spectrogram images and then use a CNN-based architecture for classification. The paper presents an innovative strategy for a CNN-based neural architecture that learns a sparse representation imitating the receptive neurons in primary auditory cortex in mammals. The feasibility of the proposed CNN-based neural architecture is assessed for audio classification task on standard benchmark datasets such as Google Speech Commands datasets (GSCv1 and GSCv2) and UrbanSound8K dataset (US8K). The proposed CNN architecture referred to as Braided Convolutional Neural Network (BCNN) achieves 97.15%, 95% and 91.9% average recognition accuracy on GSCv1, GSCv2 and US8K datasets respectively outperforming other deep learning architectures.
Harsh Sinha
Graduate Student
My research interests include computer vision, biometrics, domain adaptation, machine learning.